Configuring extended capabilities in devs.ai using additional data sources and actions
The Devs.ai platform provides a suite of configurable actions that extend your AI's functionality, allowing it to perform specialized tasks, interact dynamically with users, and retrieve knowledge from stored data.
API Function
Add Add API Actions that can be invoked during interactions with your AI.
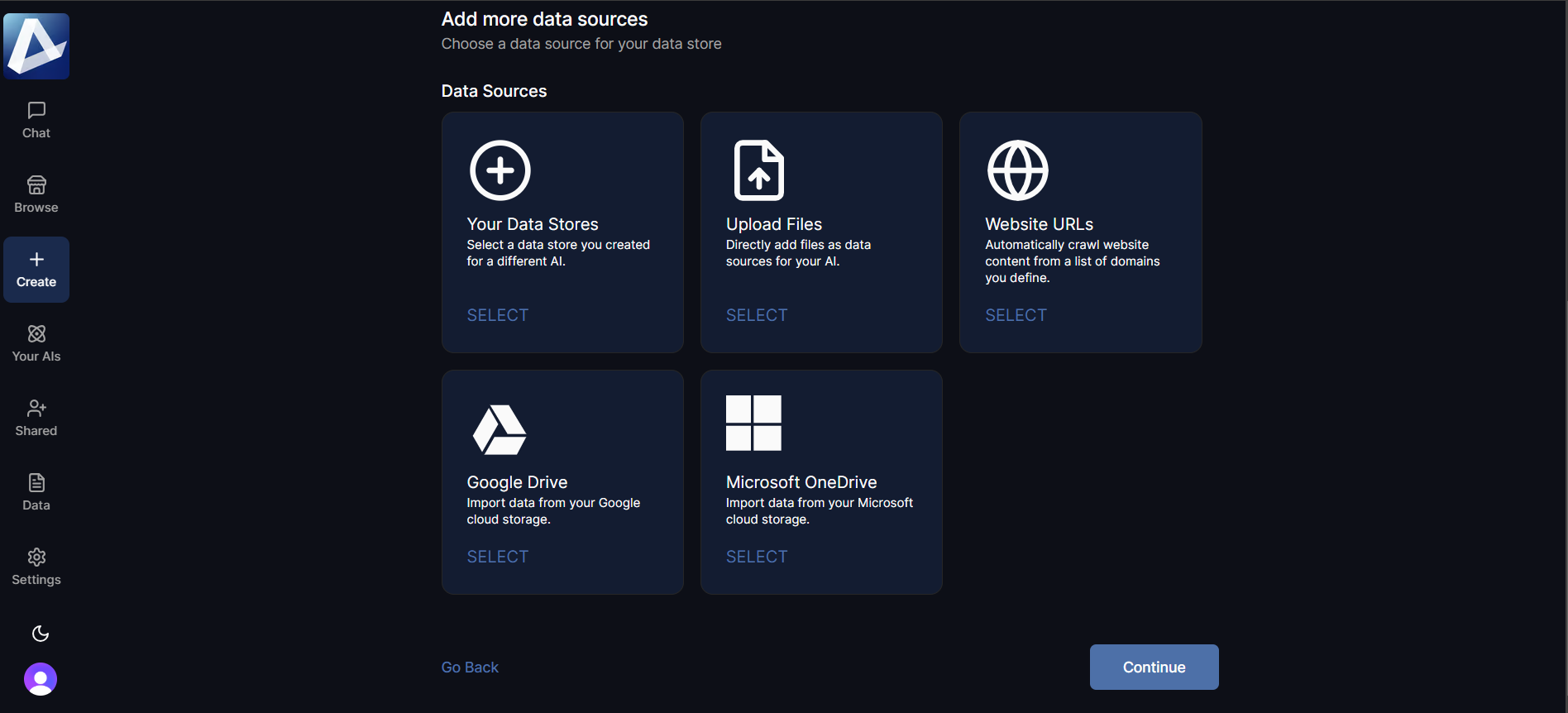
Python
Enabling Python allows your AI to perform actions on files and execute custom Python scripts generated in response to specific queries. This capability is especially useful for tasks requiring data analysis, file processing, or other automated actions that require custom scripting. Select the Python option and load a Python interpreter as a data source to work with Python scripts during conversations with your AI.
AI can install any Python packages within its environment. You can add detailed instructions about which packages to use. This will help generate scripts faster. Scripts generated using an AI have access to uploads within both conversation threads and data sources.
📝 Note: Execution using Python is limited to 5 minutes.
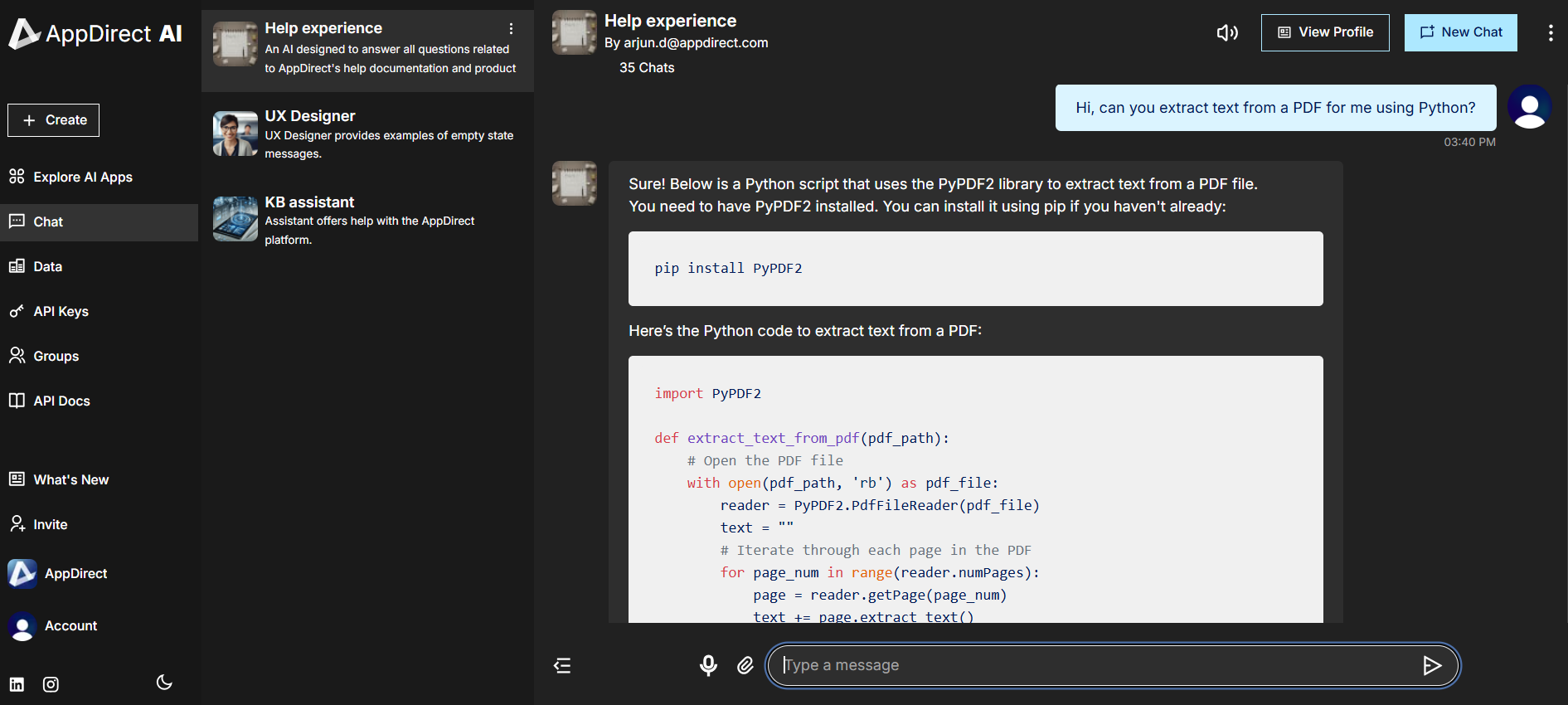
Without the Python tool enabled, an AI cannot run any scripts directly. It can only guide you on how to use scripts to perform any related tasks. For example, see below to understand how the AI responds with and without the Python tool loaded when working with some PDF related tasks.
When the Python tool is not enabled and you request for text to be extracted from a PDF:
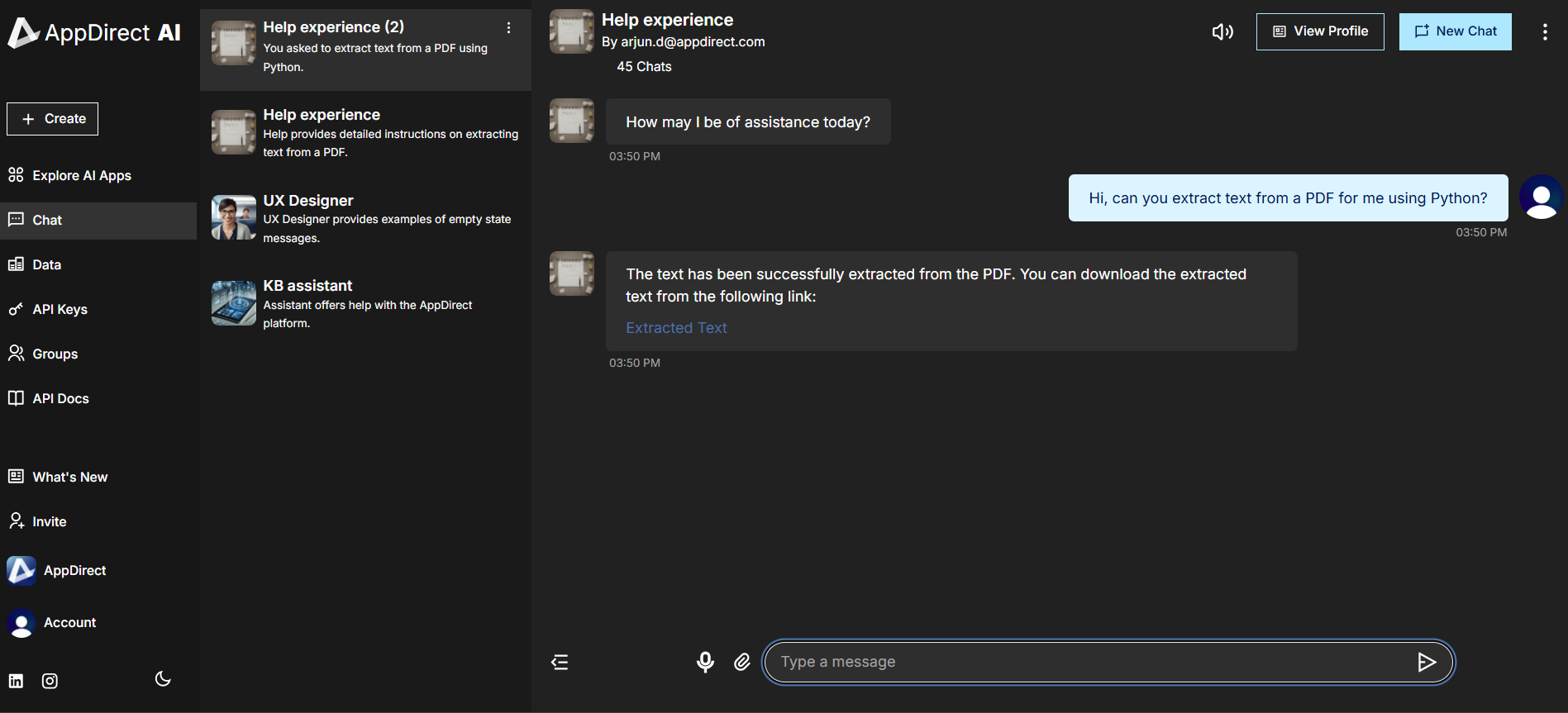
With the Python tool enabled, the AI proceeds to extract text using a script which runs in the background, provided you have uploaded the PDF to the AI’s knowledge base:
User Inputs
With this option enabled, AIs can prompt users for specific inputs directly within a chat. Based on the query, it generates input fields in real-time, allowing users to provide the necessary data seamlessly. This feature is ideal for gathering user-specific details, ensuring that responses are customized and relevant.
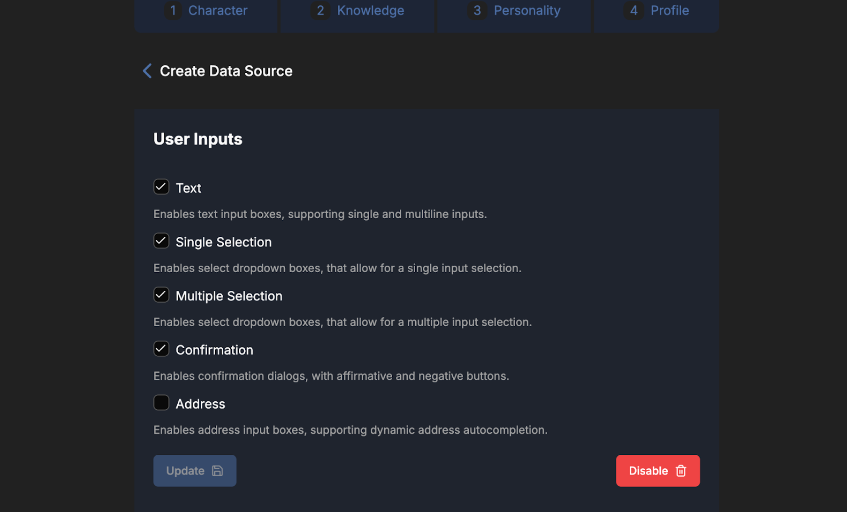
A great use case for utilizing input fields in a conversation with an AI is an address field. For instance, if you are building an AI to provide data based on a specific location, you can configure the AI to include an address input field. This field ensures users enter a valid address by leveraging the autocomplete functionality powered by Google Maps APIs. The AI would render a text field that dynamically suggests accurate addresses when you start typing.
📝 Note: For the best results, provide clear and well-defined instructions when using this feature.
Knowledge Retrieval
📝 Note: This feature is still in Beta.
The Knowledge Retrieval feature enables AppDirectAI to access relevant information from a vector store built from uploaded data sources. With this feature, the AI can efficiently retrieve and utilize stored knowledge, providing answers based on a comprehensive, customized database.
Also known as Retrieval-Augmented Generation (RAG), this process follows a sequential operation flow, where each step's output feeds into the next.
How It Works
-
Expand Queries (optional):
If enabled in advanced options, this step broadens the search by generating multiple related queries based on the original query. This expands the scope of retrieval to include a wider variety of relevant documents. -
Retrieve:
Retrieves documents that match the query from the vector store. You can set a limit for the number of documents to retrieve. -
Deduplicate:
Removes duplicate results when files appear across multiple data sources. -
Rerank:
Ranks documents based on relevancy using a dedicated machine learning model, which improves on the initial vector store ranking. Adjusting the retrieval document limit can improve accuracy and reduce noise. -
Enrich:
Adds metadata from the database to the retrieved documents. -
Grade:
Assesses document relevancy using a large language model (LLM). Relevant segments are highlighted, and documents receive a relevancy score from 0 to 10, with 10 being the highest. You can select an LLM for grading, though lighter models, such as GPT-4o Mini, are recommended to optimize data usage. Larger models may be reserved for specialized or complex topics. -
Filter:
Excludes results below the minimum relevancy score. -
Compress:
Removes irrelevant segments within documents to focus on pertinent information. -
Format:
Structures data in a format suitable for LLM processing.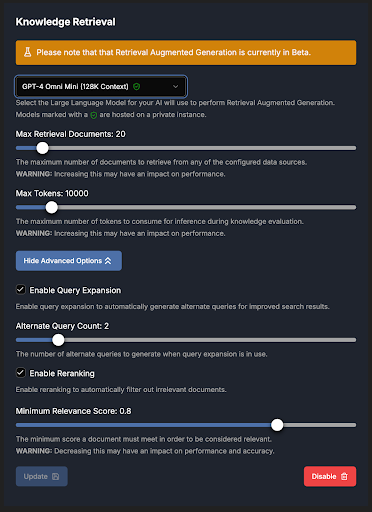
Was this page helpful?
Tell us more…
Help us improve our content. Responses are anonymous.
Thanks
We appreciate your feedback!